Introduction to TensorFlow’s data.Dataset API
tf.data.Dataset is a an API in TensorFlow that provides an efficient and flexible way to represent and manipulate data. It is used when working with large amounts of data that is going to be fed into a TensorFlow computational graph.
I had a really hard time understanding how to work with tf.data.Dataset module. So, I decided to explore the documentation of its most common methods.
If you are a complete noobie with TensorFlow (just like I was), checkout my previous blog post on “basic tensor creation and manipulation with TensorFlow”
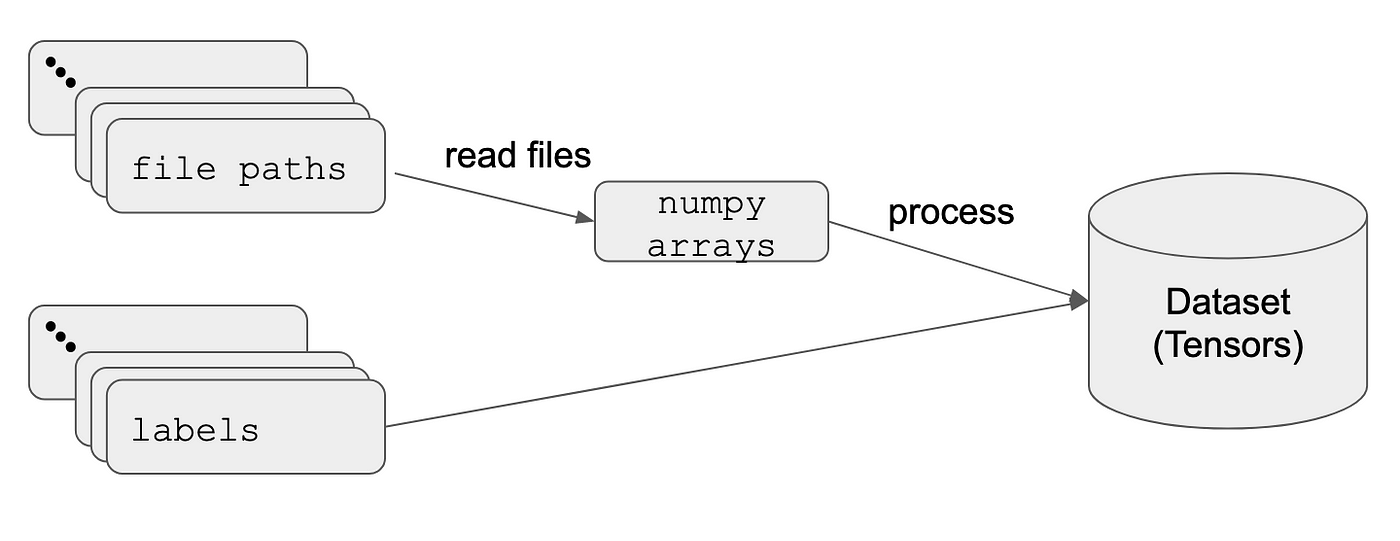
What’s the point of tf.data.Dataset?
Neural network models are data hungry. Due to memory limitations and training efficiency issues, the data needs to be transformed into tensors, split to batches and fed with an iterator. Besides the data, the model also needs the labels.
What usually happens is that we have the raw files (let’s say images) and their labels (can be part of the file name, folder name or from a csv file with metadata). We create a dataset object with the paths and labels, then, iterate over it to read the data and finish with more processing. In the end, our dataset is a tensor that contains the raw numpy data and its labels.
Loading data
data scenarios:
- All of the files are stored in one folder and the metadata (paths, and labels) is stored in a csv file.
import pandas as pd
import tensorfow as tf
df = pd.read_csv(csv_path)
dataset = tf.data.Dataset.from_tensor_slices(
(df["file_path"].values, df["labels"].values)
)
# later: a function that reads the files2. The labels are in the file name
file_pattern = "/private/tmp/tf/data/*.JPEG"
# Create a dataset for the image files
image_dataset = tf.data.Dataset.list_files(file_pattern)
print(next(iter(image_dataset)))
"""
tf.Tensor(b'/private/tmp/tf/data/361_tiger_shark.JPEG', shape=(), dtype=string)
"""
# Define a function to process the file path and extract the label
def get_labels(file_path):
# Extract the label from the file name
label = tf.strings.split(tf.strings.split(file_path, "_")[-1], ".")[0]
return label
# convert paths to labels using the function above
image_dataset = image_dataset.map(get_labels)
for element in image_dataset:
print(element)
"""
tf.Tensor(b'lobster', shape=(), dtype=string)
tf.Tensor(b'sidewinder', shape=(), dtype=string)
tf.Tensor(b'tench', shape=(), dtype=string)
tf.Tensor(b'goldfish', shape=(), dtype=string)
tf.Tensor(b'shark', shape=(), dtype=string)
"""
########################### 2nd option ################################
# create a file list and a lablel list with pathlib
# and then create the dataset
from pathlib import Path
# get all image paths
paths = [x for x in Path("/private/tmp/tf/data").glob("*.JPEG")]
# extract labels from paths
lables = [x.with_suffix("").name.split("_")[-1] for x in paths]
# conver PosixPath to string
str_paths = [str(x) for x in paths]
dataset = tf.data.Dataset.from_tensor_slices((str_paths, lables))
print(next(iter(dataset.as_numpy_iterator())))
"""
(b'/private/tmp/tf/data/695_lobster.JPEG', b'lobster')
"""
3. The data is split to a positive folder and a negative folder
neg_paths = [str(x) for x in Path(".../data/negative").glob("*.JPEG")]
pos_paths = [str(x) for x in Path(".../data/positive").glob("*.JPEG")]
neg_dataset = tf.data.Dataset.from_tensor_slices((neg_paths, [True] * len(neg_paths)))
pos_dataset = tf.data.Dataset.from_tensor_slices((pos_paths, [False] * len(pos_paths)))
dataset = neg_dataset.concatenate(pos_dataset)
print(next(iter(dataset))[0])
print(next(iter(dataset))[1])
"""
tf.Tensor(b'.../data/negative/695_lobster.JPEG', shape=(), dtype=string)
tf.Tensor(True, shape=(), dtype=bool)
"""Side note: examine the dataset
To avoid and to debug shape issues, it is important to see that we get the expected results. Here are a few options:
# Iterate over the elements.
# iterating over the elements consumes them - the loop can be executed once
for element in dataset:
print(element)
"""
(<tf.Tensor: shape=(), dtype=string, numpy=b'/tmp/tf/data/695_spiny_lobster.JPEG,'>, <tf.Tensor: shape=(), dtype=bool, numpy=True>)
(<tf.Tensor: shape=(), dtype=string, numpy=b'/tmp/tf/data/361_tiger_shark.JPEG,'>, <tf.Tensor: shape=(), dtype=bool, numpy=False>)
(<tf.Tensor: shape=(), dtype=string, numpy=b'/tmp/tf/data/291_sidewinder.JPEG,'>, <tf.Tensor: shape=(), dtype=bool, numpy=True>)
(<tf.Tensor: shape=(), dtype=string, numpy=b'/tmp/tf/data/764_tench.JPEG,'>, <tf.Tensor: shape=(), dtype=bool, numpy=False>)
(<tf.Tensor: shape=(), dtype=string, numpy=b'/tmp/tf/data/537_goldfish.JPEG'>, <tf.Tensor: shape=(), dtype=bool, numpy=False>)
"""
# if we have many elements, this will be messy. so we can use .take():
n = 2
taken_elements = list(dataset.take(n))
for element in taken_elements:
print(element)
"""
(<tf.Tensor: shape=(), dtype=string, numpy=b'.../data/695_spiny_lobster.JPEG,'>, <tf.Tensor: shape=(), dtype=bool, numpy=True>)
(<tf.Tensor: shape=(), dtype=string, numpy=b'.../data/361_tiger_shark.JPEG,'>, <tf.Tensor: shape=(), dtype=bool, numpy=False>)
"""
# for easier analysis or visualization we can
# convert dataset elements to numpy arrays
numpy_iterator = dataset.as_numpy_iterator()
taken_elements = list(numpy_iterator)[:3]
for element in taken_elements:
print(element)
"""
(b'.../data/695_spiny_lobster.JPEG,', True)
(b'.../data/361_tiger_shark.JPEG,', False)
(b'.../data/291_sidewinder.JPEG,', True)
"""
# or, just look at the elements one at a time
print(next(iter(dataset.as_numpy_iterator())))
# or look at a list of all elements
list(dataset.as_numpy_iterator())
Reading the Files
So far, we got the paths and the labels into the dataset, but we are still missing the data itself. Now we need to iterate over the file paths and use a function that reads the JEPG files as numpy arrays. Notice that the function gets the file path and the label and returns the numpy array and the untouched label.
# read csv
csv_path = "/private/tmp/tf/metadata.csv"
df = pd.read_csv(csv_path)
# create a dataset with file paths and labels
dataset = tf.data.Dataset.from_tensor_slices(
(df["path"].values, df["label"].values)
)
# function to read the files as numpy arrays
def read_image(path):
# Read the contents of the file
image = tf.io.read_file(path)
# Decode the JPEG file into a tensor
decoded_image = tf.image.decode_jpeg(image, channels=3)
return decoded_image
# iterate over datatset and replace file paths with tne numpy arrays
dataset = dataset.map(lambda path, label: read_image(path), label,
num_parallel_calls=tf.data.AUTOTUNE) # run in parallelUsing num_parallel_calls=tf.data.AUTOTUNE is a convenient way to delegate the decision of parallelism to TensorFlow, allowing it to optimize the data processing performance.
Using tf.numpy_function for more flexibility
tf.io.read_file() is great for image, text , binary and serialized files. But if our data is stored in other formats we need to write a dedicated function to process them. In order to incorporate our function into a TensorFlow graph or pipeline we’ll need to use tf.numpy_function().
from SuperSpecialExampleModule import read_special_file, process_special_file
from functools import partial
def custom_read_file(path, weird_attribute):
# this function reads and processes a very rare file
file = read_special_file(path, weird_attribute)
file_as_numpy = process_special_file(file)
return file_as_numpy
#...after creating the dataset object with paths and labels as mentioned above
dataset = dataset.map(
lambda path, label: tf.numpy_function(func=partial(custom_read_file,
path=path,
weird_attribute='whatever'),
inp=[x], #A list of `tf.Tensor` objects.
Tout=[tf.float32], # what `func` returns.
), label
num_parallel_calls=tf.data.AUTOTUNE,a few comments on tf.numpy_function():
- While it’s sometimes easy to use custom/imported functions to read files, the documentation of TensorFlow recommends to avoid using
tf.numpy_function()outside of prototyping and experimentation due to some limitations. - we cannot directly write something like:
tf.numpy_function(custom_function(arg2=2), [arg1_tensor], tf.float32)because it would result in executingmy_custom_function(arg2=2)immediately and passing the returned value (result) totf.numpy_function(). The solution is to usefunctools.partial. - The custom Python function needs to accepts
numpy.ndarrayobjects as arguments and returns a list ofnumpy.ndarrayobjects (or a singlenumpy.ndarray).
Final preparation
There are a few methods that are used almost in every dataset creation: shuffle, batch, repeat, and prefetch.
- Shuffle
shuffle(buffer_size, seed=None, reshuffle_each_iteration=True)Shuffle the dataset to introduce randomness and reduce potential bias in the order of examples. It is typically applied before batching to ensure that the batches contain a mixture of diverse examples. Random shuffling is essential for good generalization and preventing the model from memorizing the order of the data. - Batch
batch(batch_size, drop_remainder=False)Combine elements of the dataset into batches. Batching allows the model to process multiple examples simultaneously, taking advantage of vectorized operations and parallelism. It is generally applied after shuffling to ensure that each batch contains a mix of shuffled examples. - Repeat
repeat(count=None)By usingrepeat(), you ensure that the dataset is repeatedly processed for the desired number of epochs or indefinitely, allowing you to train models more comprehensively or work with streaming data. It is usually applied after batching. Ifcountis not specified, the dataset repeats indefinitely, enabling an infinite number of epochs. For testing we don’t need to repeat. - Prefetch
prefetch(buffer_size)Prefetch a specified number of elements from the dataset, allowing the CPU or GPU to work on the preprocessing of the next batch while the current batch is being consumed. It is typically applied at the end of the pipeline, after batching and repeating.
So a common process with tf.data.Dataset is something like this:
# create a tensor
dataset = tf.data.Dataset.from_tensor_slices(...)
# read the files
dataset = dataset.map(lambda path, label: read_file(path), label,
num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.shuffle(buffer_size)
dataset = dataset.batch(batch_size)
dataset = dataset.repeat()
dataset = dataset.prefetch(buffer_size)Summary
tf.data.Datasetcan be frustrating to understand. I hope that this introduction helped shed some light on this module.